
I posted recently on LinkedIn starting a topic on how to enable integration in your healthcare application using HL7 and becoming an HL7 interoperability expert. The basis of using HL7 is first understanding exactly what HL7 is and how it works. By the end of this post, you will be able to look at an HL7 v2 message and be able to parse it without any fancy encoding tools.
If you are interested in my referenced LinkedIn post, you can find it here:
<IFrame title="LinkedIn Post" src="https://www.linkedin.com/embed/feed/update/urn:li:share:7065693622960095232" />
Most explanations of HL7 start with the big picture and then dive into the smaller pieces. I like to work backward when I explain new technologies. This is the same way I put puzzles together. I will study a small piece individually to figure out where it goes in the bigger picture.
If you can understand the smallest pieces, then you will be able to compile them into the big picture.
HL7 v.2 is comprised of 5 concepts:
- (Subcomponents)[#subcomponents]
- (Components)[#components]
- (Fields)[#fields]
- (Segments)[#segments]
- (Repetitions)[#repetitions]
By the way, if you want to read the official standards, you can find them at: www.hl7.org
Each of these concepts is associated with an encoding character. You can override these encoding characters, but for now, we'll keep with the defaults.
- Subcomponents are separated by the ampersand symbol &
- Components are separated by the caret symbol ^
- Fields are separated by the pipe symbol |
- Segments are separated by the return sequence \r seen in most text editors as a line break
- Repeating Fields are separated by the tilde symbol ~
Subcomponents
The subcomponent is the smallest data concept of an HL7 message and in its most
basic format is simply a string. An example might be something like Oklahoma.
There is nothing in HL7 that signifies the difference of a subcomponent out of
context as anything other than a string. The location of the subcomponent within
the message is what assigns it a more specific data type. For example, given the
subcomponent value of 20230527, we have no idea by itself what it is other
than a string. We might want to assume it is a date, but without knowing its
position in the message, it can only be known to be a string. If we assume it
was a date, we might later be proven incorrect when it was a unit of
measurement. Later in this post, we will discuss how to identify data types
given the position, or path, to the data.
Given the default subcomponent separator, we can join multiple subcomponents
together which might look like OK&Oklahoma. Indexing in HL7 usually uses a
1-based index. This means that the first item in the separated list of items is
assigned the path 1, the second item 2, etc. So given this list of
subcomponents OK&Oklahoma we can separate them as the list:
OKOklahoma
We might assume that this is a list of a US state abbreviation in position 1,
and a state name in position 2, but we don't know at this point exactly what
this data represents.
Components
Components are simply defined as groups of subcomponents. You have already seen
two subcomponents, without really knowing it. 20230527 and OK^Oklahoma are
both components. The first one, is only a single subcomponent, while the second
one is a list of two subcomponents.
With the default component separator of the caret (^), we can start to join
together subcomponent groups into lists of components:
T123456789^^^OK^DL^^20230527^20280531^OK&Oklohoma^DMV
Components follow similar indexing patterns as subcomponents using a 1-based index scale. We can represent this list of components above into the following structure:
T123456789OKDL2023052720280531OK&OklohomaOKOklahoma
DMV
Notice how positions 2, 3, and 6 are empty. With just being empty, we
cannot be confident whether the values were empty, or if the message sender just
didn't include values in those positions. To signify that the value is indeed
empty and not just not included, the syntax is to use an empty quoted string
(""), which could look something like:
...^""^^...
With this, we know that position two was included and that it was indeed an empty value.
Let's start putting together paths for the component in the ordered list above.
We can combine a component and subcomponent path with either a dash (-) or a
period (.) like 9-2 or 9.2. So 9.2 equals the data Oklahoma. And the
data OK is found in two paths, 9.1 and 4. When a component only has a
single subcomponent, then it is common practice to leave off the subcomponent
path. In our example though, both 4.1 and 4 would reference the same value
OK. We can also reference things that don't exist in our component such as 9.3
or 12. If something is referenced but does not exist in the component, then
depending upon the handling of your environment, it may be returned as either
null, undefined, an empty string (""), or even a reference error.
You will find other resources mix and match these separators of a dash -
and a period . interchangeably. It is my personal practice to use a period .
when writing the path between components and subcomponents.
Fields
You might have already come to the logical conclusion, that a field, is the combination of multiple component groups, and if so, then you are correct. So to say it similarly again, you have already seen a field, even though you didn't know it. The component list above forms a field.
Knowing from above that the field separating character is the pipe symbol (|),
you might have already figured out what a field set would look like. But to make
it clear, here is an example:
STF|amaster507^^L|T123456789^^^OK^DL^^20230527^20280531^OK&Oklohoma^DMV|
Now let me throw a curveball at you, this example, is a list of 3 fields. You
might be wondering why that is a curveball. And that is for a few reasons. First
of all, when a list of items ends with a separator, it is declaring an
additional item in the list. Sort of like how some programming languages for an
array, set, or map. If an array was presented as [1, 2, 3, ] we would say that
there are 4 elements in the array, the 4th element was undefined. Because the
comma was given, we knew that there was something else there, even though it was
not defined. Seeing then that this list of fields ends with the field separator
|, you might think that this list has 4 fields. But that is not correct
either, because a list of fields together form the next higher concept of a
segment, and Segments can be considered 0-based indexed. See Segments below for
additional explanation. For now, just know that if we reference field 2,
component 9, and subcomponent 2, such as 2.9.2 then we would have the
value Oklahoma. This is because the 2nd field starts with the value T123....
If we put together a list of this data so far, we get:
amaster507^^Lamaster507L
T123456789^^^OK^DL^^20230527^20280531^OK&Oklohoma^DMVT123456789OKDL2023052720280531OK&OklohomaOKOklahoma
DMV
Segments
A Segment is a named list of fields. We hinted earlier that a segment can be
considered 0-based indexed meaning that the first element's index path is 0,
which we said we would explain later, so here we are now. While you cannot
usually reference field 0 in a segment, you do reference a segment by name
directly. Given our field example, which we will show again below, you can see
that this segment has the name STF. The name of a segment must be 3
uppercase alphanumeric characters.
STF|amaster507^^L|T123456789^^^OK^DL^^20230527^20280531^OK&Oklohoma^DMV|
Building upon our path to data, we can put together the segment name STF
combined with our field-component-subcomponent path 2.9.2 and get STF-2.9.2.
Again, just like with path joins between fields, components, and subcomponents,
the separator can be either a dash (-) or a period (.). I find it common
practice to use a dash after the segment name, and then a period for the other
path separators.
The name of the segment begins to give us context to the data we have. With just a single segment, and assuming a few things such as the message version, and default encoding characters, we can derive data types.
Because no one is expected to remember everything, I still use a reference to look up data types often. My go-to reference of choice is Caristix.com.
If we look up the segment STF we will get the "Staff Identification" from the "Personnel Management" from chapter 15 of the HL7 v2.5 standard. We furthermore can see that field 2 is the "Staff Identifier List" conforming to data type "CX". If we continue to look up the datatype CX (aka "Extended Composite ID with Check Digit") we will find position 9 to be the "Assigning Jurisdiction" conforming to datatype "CWE". I know it seems tedious, but keep going down the trail, and you will find that data type CWE (aka "Coded with Exceptions") 2nd position is the "Text" and conforms to just the ST (aka "String") data type. So this means that STF-2.9.2 is the STF Staff Identification - 2 Staff Identifier List . 9 Assigning Jurisdiction . 2 Text.
You might think that doesn't make much sense, but let's decode one more path, STF-2.5. This will lead you to table 0203 which tells you the value DL maps to the "Driver's License Number". Now for security's sake, I would not post my actual driver's license number, but as you now can put together, my driver's license was assigned under the jurisdiction of "Oklahoma".
Since Segment names must be 3 characters followed by a field separating character, it can be determined that field 1 of a segment begins with the 5th character. However, there is one exception to the rule! The MSH (aka "Message Header") segment defines the encoding characters with fields MSH-1 and MSH-2. The MSH-1 (aka "Field Separator") is the literal first field separator found at character 4 of the MSH segment.
Normally the first 9 characters of MSH are similar to:
MSH|^~\&|
Defining the usual encoding characters as:
- Field Separator (
|) - Component Separator (
^) - Repeat Separator (
~) - Escape Character (
\) - SubComponent Separater (
&)
But, there is no limitation on these ecoding characters, and the message could look like:
MSH*.#/+*
Which would change the encoding characters to:
- Field Separator (
*) - Component Separator (
.) - Repeat Separator (
#) - Escape Character (
/) - SubComponent Separater (
+)
As you peruse HL7 dictionary resource specifications, you will find a thing
called "OPTIONALITY". Some fields are always Required, but many others are
Optional. When you start using HL7 with vendors, you will find vendor
specifications. These specifications usually can override the standard
specification in terms of what they require and allow it to be optional. This
can help alleviate situations with seemingly overlapping data. For instance,
STF-2.4 and STF-2.9 might be overlapping data depending on the exact use
case specifics, and one or even both of these fields might be completely omitted
if the vendor does not find it necessary data to send and/or receive.
Repetitions
In HL7 v2.x, fields and segments can repeat depending upon the allowable
datatype. In Caristix, the repeatability of fields are denoted with - meaning
no repeats allowed, a number indicating how many repetitions are allowed, or the
infinity symbol ∞ indicating unlimited repetitions are permitted. Segments are
repeated without any special repeating indicators. For example, the NK1 (Next
of Kin/Associated Parties) segment, can usually depending upon the vendor, allow
for repeating segments. This could be exemplified to show both my wife and my
mother:
NK1|1|Master^Amanda|SPO
NK1|2|Master^^^^Mrs|MTH
Depending upon your environment and configuration, you may now get an error when
trying to reference my "Next of Kin"s family name with NK1-2.1. This would be
because there is ambiguity as to which NK1 segment you are requesting. To
clear this up, you would add an iterator index to the repeating segment's name.
The syntax and indexing base vary by your environment, but it is commonly
1-based indexed and syntax with the iteration surrounded by brackets. So to
reference my first next of kin's relationship, we would use STF[1]-3 which
finds us SPO (aka "Spouse").
Field repetitions take a slightly different form. When a field repeats, each
iteration is separated with the field separating encoding character (MSH.2 2nd
character) which is normally the tilde (~). Let's show an example and then
explain it:
STF|amaster507|T123456789|MASTER^ANTHONY^LEE^^^^L^A~^TONY^^^^^N~MASTER^ANTHONY^^^BRO^BATh^REL|C^CANDIDATE|M
Looking at STF-3 (aka "Staff Name") you will see two repetition characters. This shows that there are three names given for this person. Looking a little deeper at STF-3[*].7 you will find the values L, N, and REL. Using Table "0200" with version v2.7, you can map these to the "Official Registry Name", "Nickname", and "Religous" name types. You were also just introduced to a new syntax, the field follows by brackets ([ and ]) wrapping an iteration index. Field iterations are always 1-based indexed. If we know that the second name is the nickname, then we can extract my nickname with STF-3[2].2 which would be TONY.
Most of the time, repeating fields are not typed in the same order. Meaning that given two separate messages with different staff, one could have an STF-3[2] referencing a nickname, while another is either missing that iteration altogether or it is a completely different name type such as maiden name. It is important then to check for contextual indicators such as the STF-3[*].7 to ensure the correct field is being referenced.
Messages
An HL7 message is the composition of one or more segments. The first segment in a message will be the MSH (ak "Message Header") segment.
This wraps up the main concepts of the syntax of an HL7 v2.x message. Before wrapping up this article though, I want to briefly cover three more important factoids and a fourth for your own, personal research:
Escaping Encoding Characters.
You might be wondering, what if one of the special encoding characters is used inside of a textual data element? For instance if "Little Bobby Tables" shows up in your message?
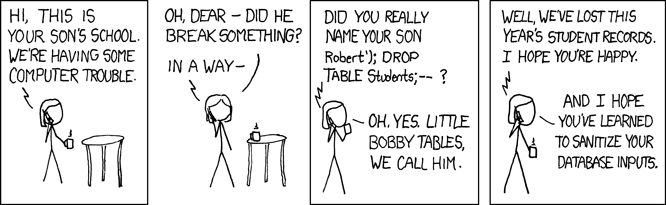
To cover these scenarios, there is another encoding character called the "Escape
Character". The default escape character is the backslash (\) which can
undoubtedly be cumbersome to work with in some editors and environments. This
encoding character can be customized using the MSH-2 field's 3rd character.
With this escape character, you can now safely include "Little Bobby Tables" and
all other correctly escaped free text input into your messages as well.
Message Trigger Events
Without getting into all of the specifics and differences between HL7 v2.x and FHIR (v4), I will at least introduce the idea that v2 varies from FHIR in that v2 uses the concept of a messaging event system whereas FHIR uses the equivalence of a RESTful API. If you are not familiar with the terms "messaging event system" and "RESTful API", I highly encourage some additional research into those terms.
In HL7 2.x it is common for "Interfaces" to contain similarly typed messages. A
common interface is the ADT interface that transmits and/or receives messages
concerning Admits, Discharges, and Transfers of patients within a
healthcare organization. Each message indicates its code in field MSH-9.1. And
then another layer into these coded interface types are the trigger events. A
trigger event describes what event happened that triggered the message to send.
For a quick example, here are just 4 of the many ADT trigger events:
A01: Admit/visit notificationA02: Transfer a patientA03: Discharge/end visitA08: Update patient information
Message Versions
The message version can be found for each message in the MSH-12 field.
Depending upon this message version the data types, optionality, repeatability,
tables, and dictionaries will vary. It is common practice to conform an
interface to a specific message version. Some vendors may mix versions depending
upon supported specifications within each version. Consult your vendor's HL7
specification guides for more details regarding which versions are supported
within which interfaces/events.
Message Batching
Message Batching involves handling a batch of HL7 messages in a single stream or file. Batching is usually used by systems that do not communicate in real time but rather in scheduled batches.
Batched Files still follow the same HL7 syntax, but wraps each message with a Batch Header Segment BHS and Batch Trailer Segment BTS, and wraps the entire file in a File Header Segment FHS and File Trailer Segments FTS.
This can be shown by the HL7 Standard specification:
[FHS]
{
[BHS]
[
MHS
...
]
[BTS]
}
[FTS]
There are challenges and exceptions for handling batched message files, and sometimes batching rules are ignored and some other custom batching syntax might be implemented by vendors.
A reason for using schedule batches instead of real time events could be for reducing network/server overhead and/or reduce attack surface of your system by removing TCP listeners and using other protocols such as SFTP or HTTPS.
Summary
Thank you for taking the time for me to explain to you the main concepts and fundamentals of understanding HL7 v2.x messages. You should now be able to put your skills to use. I'd love to hear your feedback and continue the discussions.
Originally published on dev.to